延續上回提到的架構圖,今天我們從架構圖的上方開始介紹。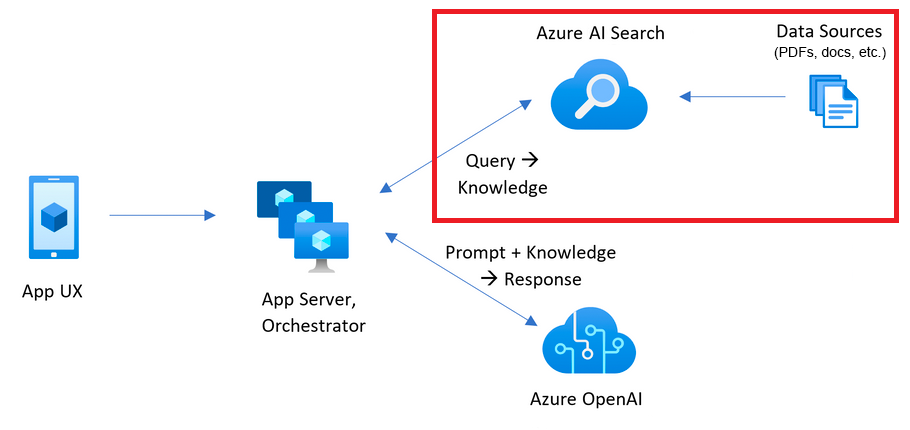
資料來源就是我們平常習慣閱讀的各類檔案,格式可能是PDF文件、PNG圖檔等等。資料量少時,可能還容易消化,但資料大時,就像走入一個圖書館門口,若沒有透過事先查詢索書號,再到對應的架上尋找所需要的書籍,要在茫茫書海中找到想要的資訊是相當困難的。這個時候,事前準備好這些參考資料的來源檔案,交給聊天機器人幫忙我們處理這些繁瑣的查找工作吧!
蒐集好了這些文檔後,機器人還沒辦法馬上理解這些文件內容,此時,我們就可以使用Azure AI Search,Azure官網是這麼介紹這項服務的
使用專為進階擷取擴增生成 (RAG) 和現代式搜尋所建立的向量資料庫,提供高品質的回應
也就是說,Auzer AI Search不只有字面上的搜尋功能,它其實才是聊天機器人真正的知識庫,將人們習慣閱讀的文件轉換後,這些文件內容透過向量資料的方式儲存起來,再透過資料檢索進行後續的查找。如此一來,聊天機器人彷彿具備一目十行的能力,能夠透過這個搜尋引擎,快速地找到關鍵資訊。
下一篇,我們將進一步說明,資料內容是如何從文檔的格式進到Auzer AI Search之中。
Adobe Firefly(AI圖片生成)
azure-search-openai-demo
Azure AI Search
今天是中秋節,月圓人團圓,大家有出門賞月或烤肉嗎?筆者從來沒想過會有一年的中秋節是在撰寫鐵人賽的文章,想必會成為之後很特別的回憶之一。放假的日子,時間總是過得特別快,人也特別快樂呢:)


 iThome鐵人賽
iThome鐵人賽